Lacre - ongoing work
Reliability improvements
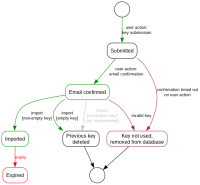
- Key lifecycle analysis and fixes. I've documented it with graphviz (see doc/key-lifecycle.gv.
- Database transactions.
- Another approach at encoding issues — there have been reports on broken encodings from Disroot users.

Research: avoiding message transformation
Python's email module provides a set of parsers for email messages, among them:
- BytesParser, which just consumes a
bytessequence and produces anEmailMessage, with all of its data and meta-data kept in memory; - BytesHeaderParser, which only parses headers and doesn't provide features to access parts of a multi-part message.
The problem with the first approach is that if we choose to encrypt an EmailMessage, its contents is serialised by an appropriate email.generator implementation, instead of producing the original content. This is OK for payloads like text in pure ASCII or Unicode with Latin scripts, but things get tricky when we want to transfer non-Latin scripts (e.g. Japanese, Chinese, or any of the Cyrillic alphabets). (This is mostly caused by different Content-Transfer-Encoding being chosen by email.generator.)
BytesHeaderParser and its string counterpart let us only parse the headers and keep original message body in memory. The drawback is that we can't process multipart messages as sequences of MIME entities, which we need for one of the Lacre's modes of operation. (There are two: PGP/MIME with whole body encrypted and PGP/Inline with each part of multipart message encrypted separately.) We could use BytesHeaderParser with PGP/MIME only, because a multipart message would be impossible to handle in PGP/Inline mode.
Research: avoiding message transformation (part 2)
It turns out that we can avoid some of the transformations:
- For messages in cleartext, already encrypted and those processed in PGP/MIME mode we could just take original message content (Envelope.original_content) and process it. Thus we'd avoid using email.contentmanager, which is the component responsible for decoding MIME entities.
- Messages processed in PGP/Inline mode would risk being transformed before encryption.
To achieve that, we'd need to adjust the flow and:
- Work with a plain
Envelopeinitially to identify identities and prepare for encryption. - We could use header-only parser mentioned above during delivery planning (
lacre.core, functiondelivery_plan). - Finally, if the message is known to be processed in PGP/Inline mode, we could load each MIME entity's body and process it. (Without ContentManager if possible.)
Research: Thunderbird's handling of OpenPGP-encrypted messages
Turns out when Thunderbird is expected to send a plain text message (something that would usually become a text/plain MIME entity accompanied by a bunch of headers), it does the following:
- It creates a
multipart/encryptedMIME entity (RFC 4880 and 3156 compliant); - creates a
multipart/mixedMIME entity; - populates its contents;
- encrypts it and puts in the MIME entity from step 1.
Populating the contents depends on the mode:
- If
Subject:is encrypted too, originalSubject:is replaced with the string…. - If the user chooses to sign the message, their public key is included in the
multipart/mixedentity. - Actual message body is included as Base 64-encoded MIME part of the
multipart/mixedentity.
Unfortunately we need to compose new MIME entity for every PGP/MIME-encrypted message, so we need to load contents of each part. To avoid transformation we could switch from get_content() to get_payload(decode=False), so we'd get strings with raw MIME entity payloads, giving us a chance to populate multipart/mixed in step 2 above with non-transformed payloads.